Hadoop Architecture Guide 101
-
 By Niveditha
By Niveditha - Published on Apr 12 2023

Table of Contents
Introduction to Hadoop
Hadoop was introduced on April 1, 2006, and developed by Apache Software Foundation. The developers or authors of Hadoop are Michael J. Cafarella and Doug Cutting.
Hadoop is open-source software used for storing data and running applications, grouped to export hardware.
Hadoop is used effectively to store and process a wide range of datasets of size, from GB-PB. Hadoop is used by great organizations like Facebook, Apple, IBM, Google, Twitter, and hp. What makes Hadoop reliable? Let us learn in detail.
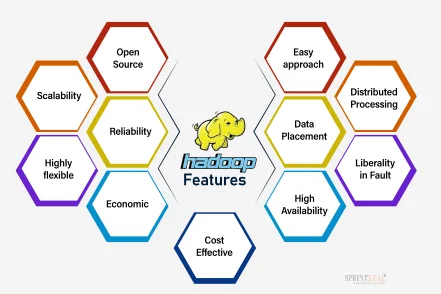
Features of Hadoop
Hadoop features are what make it more impressive. They are as follows,
• Open Source
• Highly flexible cluster
• Liberality in Fault
• Easy approach
• Cost Effective
• Data Placement
Features of Hadoop make it adaptable and easy-to-use software.
Similarly, Hadoop architecture is used to understand certain software applications. Let's learn in detail about what makes Hadoop architecture an effective solution.
Learn more and get trained by the experts through Sprintzeal.
Hadoop Architecture Explained
New things are being introduced and developments are being done for a better future in technology, one among them is Hadoop. Hadoop has become an effective solution in today’s time. It carries an impressive set of goals across various hardware platforms.
Hadoop's effective work performance regarding Hadoop architecture makes it essential to use open-source software. Let us understand the importance of Hadoop architecture in detail.
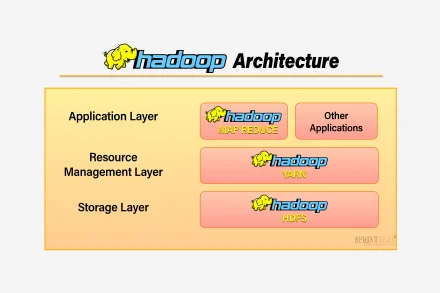
Hadoop Architecture acts as a topology, where one primary node contains multiple child nodes. Primary nodes assign several tasks for child nodes to manage resources. The child node or the sub-node does the actual work of computing. The child node stores the real data whereas the primary node holds the metadata meaning data is stored within data.
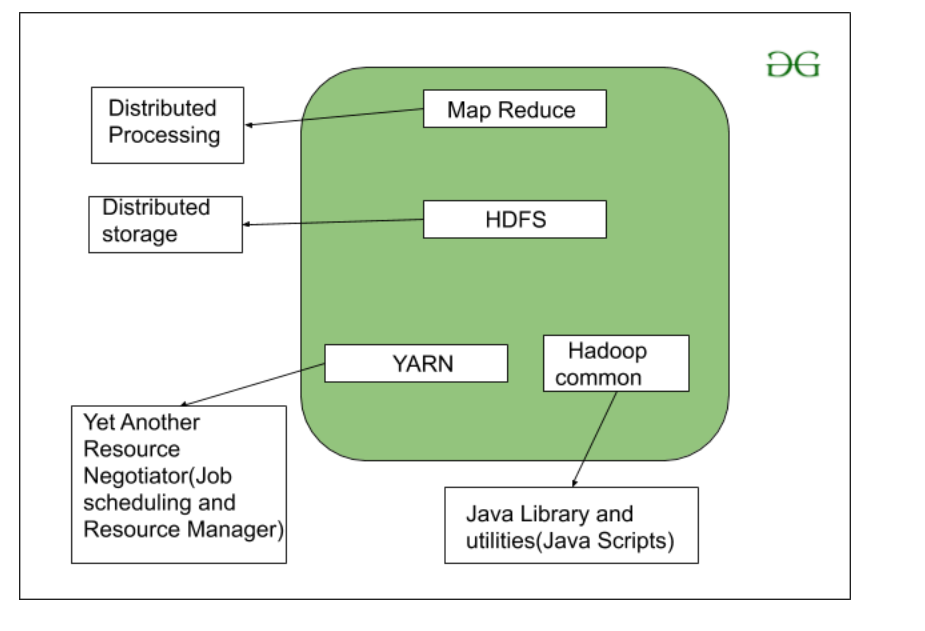
Let us understand the Diagram of Hadoop Architecture and its applications in detail.
{kind=link}
The Diagram of Hadoop architecture contains three important layers. Those are as follows,
HDFS (Hadoop Distributed File System)
Map Reduce
Yarn

About HDFS
Hadoop Distributed File System HDFS Architecture enables data storage. Enabled data is converted into small packets or units known as blocks. The converted data is then stored in a distributed way. It has two different domains running one for the primary node and one for the child node.
HDFS architecture in big data considers the Primary node as NameNode and other child nodes as a data node. Let's learn in detail,
NameNode and DataNode
HDFS is a Primary-Slave architecture that runs the NameNode domain as the master server. Here it is in charge of namespace management and modulates the file access by the client.
DataNode runs on the child or the sub-nodes as it stores the required business data. Here the file gets split into several blocks and stored in the sub machines.
NameNode keeps track of the mapping of blocks to DataNodes. Adjacent to that DataNodes read/write requests. Then forward it to the client’s system file. DataNodes also create, delete and repeat the demanding blocks of NameNode.
Block in HDFS
Blocks are small packets of storage in the system. The neighboring smallest storage value is allocated to a file.
Hadoop has a default block size of 128-256MB, for NameNode and DataNode.
Replication management
To provide one of the features of Hadoop, fault tolerance / Liberality of HDFs, Hadoop uses the replication technique. Where it copies the blocks and stores them on different DataNodes. Through replication, it’s decided how many copies of the blocks are to be stored. And three is the default value to configure data.
Rack Awareness
Rack awareness in HDFS is about maintaining the DataNode machines and producing several racks of data. HDFS in general follows an algorithm on rack awareness.
MapReduce
MapReduce architecture is a data processing layer of Hadoop Architecture. To process large amounts of data writing, applications are allowed through the Hadoop software framework.
MapReduce runs applications simultaneously on Hadoop cluster architecture for low-end machines. It is set to reduce tasks and each task works as per the mapped data. A load of data is distributed across the group so the data can be filtered and transferred.
And there is stored data on HDFS as an input file of map-reduce which is split and processed to store as HDFS replications. Let’s go through the phases that occur and the process in detail.
Map Task
Map task contains phases mentioned below,
Record Reader
The record reader converts input split (logical split) into records. It claims only data into records but does not claim records in single. The Map function is provided with key-value pairs. Keys hold the positional information and value holds the data record.
Map
The Mapper or the Map contains the subroutine of a key-value pair from the record reader. It contains zero or multiple midway key-value pairs.
The precise key-value pair is decided by the mapper function. Data that gets aggregated gets the final result from the reducer function.
Combiner
A combiner is a localized reducer that helps group the data in the map phase.
Partitioner
It performs a set of modulus operations with the help of reducers in numbers. The partitioner is all about getting the intermediate key-value pair from the mapper.
Reduce Task
There are certain phases involved in reduce tasks which are as follows,
Shuffle and sort
Individual data pieces are sorted into large data lists. The data written by the Partitioner is downloaded to the machine where the reducer is running.
Shuffle and sort are about controlling and sorting the keys, in alignment. Where the tasks could be performed easily and a sorted object is given.
Reduce
Reduce performs the function of reduction as per key grouping.
Reduced function gets the end key-value pairs to the output format, and gives zero as the reduced value. It is similar to the map function as changing from one task to another.
OutputFormat
It is the final task where the key-value pair from the reducer is written by the record writer. Each key is separated to have a new record by a newline character. The final output is written to HDFS.
YARN
Yet another Resource Negotiator is a resource managing layer for Hadoop architecture. The main goal of yarn is to separate the resource and monitor functions into separate domains.
YARN architecture contains one global resource manager and an application master, for every single job.
The domain resource manager and application masterwork with the node functions will execute and complete the job. And the resource manager from Hadoop yarn architecture contains scheduler and application manager as two important components to negotiate.
The scheduler is the one that allocates resources to applications.
Application manager performs certain functions through the application master and they are as follows,
• Negotiates resources of the scheduler.
• Keeps track of resource
• Monitors the application to be in progress.
Features of YARN
The yarn contains four major features in Hadoop, which are as follows,
Multi-tenancy
It has access to various engines on the same Hadoop data set.
Cluster Utilization
Dynamic allocation of resources, where static reduces in map compared to previous versions of Hadoop with lesser utilization of groups.
Scalability
The strength of data keeps on increasing as data is processed in petabytes PB.
Compatibility
Without any interruption, work can be completed using yarn. No disruption occurs as it acts as a map-reduce program for Hadoop.
| Learn in detail about Hadoop with Big Data Hadoop and Spark Developer Course |
Conclusion
Hadoop is a very powerful open-source software developed for system work. Hadoop architecture in big data is effective with reliable software applications. With Hadoop, it’s made easy to interact with greater platforms.
Learn about Hadoop to make a good start in your cloud computing career, enroll in Sprintzeal's Big Data Hadoop Training program.
Subscribe to our Newsletters
Niveditha
Niveditha is a content writer at Sprintzeal. She enjoys creating fresh content pieces focused on the latest trends and updates in the E-learning domain.
Popular Programs





Trending Posts

Data Structures Interview Questions
Last updated on Aug 22 2022
")
Big Data Guide – Explaining all Aspects 2024 (Update)
Last updated on Dec 12 2022

Fundamentals of Data Visualization Explained
Last updated on Apr 16 2024
")
Top Hadoop Interview Questions and Answers 2024 (UPDATED)
Last updated on Nov 24 2022

What Is Data Encryption - Types, Algorithms, Techniques & Methods
Last updated on Jul 26 2022

How to Become a Data Scientist - 2024 Guide
Last updated on Jul 22 2022
Categories
- Agile Management 54
- AI and Machine Learning 42
- Big Data 53
- Business Management 51
- Cloud Computing 44
- Digital Marketing 56
- Information Security 8
- IT Hardware and Networking 17
- IT Security 103
- IT Service Management 29
- Leadership and Management 1
- Microsoft Program 2
- Other 43
- Programming Language 31
- Project Management 162
- Quality Management 75
- Risk Management 8
- Workplace Skill Building 2
Trending Now
Big Data Uses Explained with Examples
ArticleData Visualization - Top Benefits and Tools
ArticleWhat is Big Data – Types, Trends and Future Explained
ArticleData Analyst Interview Questions and Answers 2024
ArticleData Science vs Data Analytics vs Big Data
ArticleData Visualization Strategy and its Importance
ArticleBig Data Guide – Explaining all Aspects 2024 (Update)
ArticleData Science Guide 2024
ArticleData Science Interview Questions and Answers 2024 (UPDATED)
ArticlePower BI Interview Questions and Answers (UPDATED)
ArticleApache Spark Interview Questions and Answers 2024
ArticleTop Hadoop Interview Questions and Answers 2024 (UPDATED)
ArticleTop DevOps Interview Questions and Answers 2025
ArticleTop Selenium Interview Questions and Answers 2024
ArticleWhy Choose Data Science for Career
ArticleSAS Interview Questions and Answers in 2024
ArticleWhat Is Data Encryption - Types, Algorithms, Techniques & Methods
ArticleHow to Become a Data Scientist - 2024 Guide
ArticleHow to Become a Data Analyst
ArticleBig Data Project Ideas Guide 2024
ArticleHow to Find the Length of List in Python?
ArticleHadoop Framework Guide
ArticleWhat is Hadoop – Understanding the Framework, Modules, Ecosystem, and Uses
ArticleBig Data Certifications in 2024
ArticleData Collection Methods Explained
ArticleData Collection Tools - Top List of Cutting-Edge Tools for Data Excellence
ArticleTop 10 Big Data Analytics Tools 2024
ArticleKafka vs Spark - Comparison Guide
ArticleData Structures Interview Questions
ArticleData Analysis guide
ArticleData Integration Tools and their Types in 2024
ArticleWhat is Data Integration? - A Beginner's Guide
ArticleData Analysis Tools and Trends for 2024
ebookA Brief Guide to Python data structures
ArticleWhat Is Splunk? A Brief Guide To Understanding Splunk For Beginners
ArticleBig Data Engineer Salary and Job Trends in 2024
ArticleWhat is Big Data Analytics? - A Beginner's Guide
ArticleData Analyst vs Data Scientist - Key Differences
ArticleTop DBMS Interview Questions and Answers
ArticleData Science Frameworks: A Complete Guide
ArticleTop Database Interview Questions and Answers
ArticlePower BI Career Opportunities in 2025 - Explore Trending Career Options
ArticleCareer Opportunities in Data Science: Explore Top Career Options in 2024
ArticleCareer Path for Data Analyst Explained
ArticleCareer Paths in Data Analytics: Guide to Advance in Your Career
ArticleA Comprehensive Guide to Thriving Career Paths for Data Scientists
ArticleWhat is Data Visualization? A Comprehensive Guide
ArticleTop 10 Best Data Science Frameworks: For Organizations
ArticleFundamentals of Data Visualization Explained
Article15 Best Python Frameworks for Data Science in 2025
ArticleTop 10 Data Visualization Tips for Clear Communication
ArticleHow to Create Data Visualizations in Excel: A Brief Guide
ebook