Top Hadoop Interview Questions and Answers 2024 (UPDATED)
-
 By Aradhya Kumar
By Aradhya Kumar - Published on Nov 24 2022
")
Table of Contents
- Most Popular Hadoop Interview Questions and Answers in 2024
- Lists of Commonly Asked Hadoop Interview Questions and Answers 2024
- Basic Hadoop Interview Questions and Answers - Set 1
- Advanced Hadoop Interview Questions and Answers - Set 2
- Hadoop Interview Questions and Answers for Experienced - Set 3
- Top Hadoop Interview Tips
- Conclusion
Most Popular Hadoop Interview Questions and Answers in 2024
In general, the question-answer round does not involve a high level of Hadoop interview questions, but rather a trickier one which is far more objective than thought.
To be great in Hadoop, one must have to be literally a mastering writing Java. The only factor that separates Hadoop from spark is cost-effectiveness, and for a professional, with Hadoop's certification, the market offers a lot as it is still considered a niche skill.
All the Hadoop interviews that take place for a Hadoop developer focus more on the pragmatic side. That is the reason that the interviewer tends to indulge candidates more in competency mapping.
It is wise for a candidate not to take abrupt turns while you're answering, as the hiring authority focuses more on direct answers. Be crisp and clear with your responses!
Hadoop is not as fast as spark but is faster than the traditional system which is written in Java and follows batch processing in use.
This article is all about answering the most ask questions in the interview for a Hadoop developer.
Lists of Commonly Asked Hadoop Interview Questions and Answers 2024
Most of the candidates attempting to be Hadoop developers fail on the first attempt missing the frequent interview questions in Hadoop.
We have curated sets of Hadoop interview questions and answers below vital for interview preparation. Nevertheless, persistence, patience, and a strategic routine are totally key rules to cracking any interview.
Here are top Hadoop questions and answers which you can look at for a better understanding of the subject;
Basic Hadoop Interview Questions and Answers - Set 1
Here are the basic Hadoop Interview Questions and Answers,
1) What do you mean by Hadoop and its component?
The ideal way to answer this question is by sticking to the main components which are the storage units and processing framework. When it comes to defining Hadoop, you have to start with big data. Below we have provided you a sample answer to which you can relate and form your own answers.
- It is an open-source distributed processing framework for pet stores, and the process is big data. The end users can use this software and have access to a network of many computers to resolve problems related to mammoth amounts of data and its computation.
- It is commonly used for commodity hardware and is designed for computer clusters. The best part is all the common occurrences of problems and failures in the hardware his fundamentally handled by the framework itself.
- At its core, we have a storage part, which is called a Hadoop distributed file system, followed by a processing part, which is known as the MapReduce programming model. In a way, we can work on a distributed file system and has the capabilities to work in a cross-platform operating system.
- The base Apache framework consists of the following modules that contain libraries and utilities, a distributed file system for storing data on commodity machines.
- It also uses YARN which is a platform responsible for computing resources in clusters. All the large-scale data is processed through a programming model called MapReduce.
2) Define HDFS and YARN?
Hadoop distributed file system is known as HDFS, file yet another resource negotiator is known as YARN.
- HDFS is designed to store data in blocks in a diverse environment and architecture. The environment consists of a master node, which is called a name node.
This is where all the data are structured in blocks, location, and replication factors - making it to the metadata information repository.
The slave nodes which are responsible for the storage and block communication and replication factors are known as data nodes. The name node is responsible for managing all the data nodes in our master and slave topology.
- Yet Another Resource Negotiator (YARN) is defined as a processing framework that provides execution and management of resources stored in the environment. It has a resource manager who is responsible for acting upon the received processing request.
It corresponds with node managers and initiates actual processing. It works in a batch mode and allocates resources to applications based on their needs.
An old manager, which is a part of YARN, can be found in every data node responsible for the execution of the task.
Suggested Read: Hadoop Framework Guide 2024
3) Illustrate the steps to fix the name node when it is a malfunction?
H we have to follow a three-step approach in troubleshooting Hadoop cluster-up problems, and they are:
- FsImage, otherwise called metadata replica, is used to start a new name node in the file system.
- Then we start the configuration process. Further data notes, as well as the clients, are acknowledged as a new NameNode after the initiation of the first step.
- In the end, we get enough block reports from the data nodes that are loaded from the last checkpoint FsImage.
This usually takes up a lot of time to re-direct and extract the data, which may serve as a great challenge while doing routine maintenance. But with the use of high-availability architecture, we can eliminate it in no time.

4) What do you mean by a checkpoint?
This is a process that takes the request for file system metadata replica, edits the log, and further compacts them into a new FsImage.
1) Check preconditions----GET/ getimage?putimage=1------- HTTP Get to getimage------ GET/ getimage----- new fsimage data----- saves to intermediate filename-----putimage completes----- save MD5 file & renames fsimage to final desitination.
2) User------fsimage-----checkpointing-----mkdir”/foo” ----- NameNode-----edit log.
5) Illustrate how HDFS fault is tolerant?
The problem with a single machine is that in a legacy system, the relational database performs both read and writes operations by the users.
Here is a brief illustration of HDFS fault,
- If any contingency situation arises like a mechanical failure or power down from the user has to wait still, the issue is corrected manually.
- Another set of problems with legacy systems is that we have to store the data in a range of gigabytes.
The data storage capacity was limited and enhanced data storage capacity. We have to buy a new server machine. It directly fixes the cost of maintaining file systems and issues related to it.
- With the all-new Hadoop distributed file system, we can overcome storage capacity problems and tackle favorable conditions like machine failure, RAM crash, and power down.
- HDFS, otherwise known as Highly fault-tolerant, handles the process of replica creation quite intuitively, making clusters of user data in different machines.
- The main component that helps to provide stability in fault-tolerant is called Erasure Coding. It improves the quality of the replication factors and enhances durability to contingencies.
It is achieved in two ways, and they are as follows:
Replication mechanism
The idea here is to create a replica of the data block & store then in the DataNode. The replicas list entirely depends upon the replication factor that ensures no loss of data due to replicas stored on a variety of machines.
Erasure Coding
RAID or Redundant Array of Independent Disks makes practical usage of the Erasure coding by having effective space-saving methods. It can reduce up to 50% of storage overhead for each strip of the original dataset.
6) What are the common input formats in Hadoop?
In Hadoop, we have provisions made accessible for input formats in three significant categories, and they are as follows:
The input format for reading files in sequence, is also known as Sequence File Input format.
The default input format of Hadoop is known as the Text Input Format.
The format that helps users to read plain text files is called Key-Value Input Format.

7) How would you define YARN?
YARN or Yet Another Resource Negotiator is a Hadoop Data processing framework that helps to manage data resources by creating an environment or architecture for data processing.
It supports different varieties of processing engines & applications by separating tits duties across multiple components and dynamically allocating the pools of resources to desired applications.
In many ways, it is uncommon for MapReduce to on cluster resource management.
Advanced Hadoop Interview Questions and Answers - Set 2
Here are the Hadoop Interview Questions and Answers for advanced level,
8) Define Active and Passive NameNodes?
The NameNode that helps to run the Hadoop cluster resource is called the Active NameNode. While the standby NameNode that helps in the storage of data for the Active NameNode is otherwise called a Passive NameNode.
They both are the components of the High Availability Hadoop System, whose sole purpose is to provide fluidity and increase the effectiveness of the cluster and the system files.
9) Define Speculative Execution?
When the entire program runs slower just because of some nodes, then to overcome this constraint, Hadoop speculates the troubled nodes and launches a backup for the task.
A master node executes both the task simultaneously of running and backing up & the whole scenario is called Speculation Execution.

10) List out some of the main components of the Apache H base?
To be precise, there are three components of Apache H Base as follows:
H master: With the help of this tool, a user can manage and coordinate the functioning of the regional server.
Region server: It is a division of multiple reasons further into clusters of these reasons. These are then provided to the clients through the Region Server.
Zookeeper: Each tool helps us to coordinate within the H base by maintaining a server state and communication in session inside the clusters.
11) How would you debug a Hadoop code?
Firstly, check and ascertains the list of map-reduce tasks that are running at present. Further, you have to check orphaned tasks whether or not they are running simultaneously with the map-reduce tasks.
Secondly, if you find any orphaned tasks, then you have to locate it. The resource manager logs through the following steps are given below:
Step 1: Try to find out if there is an error related to a specific job ID by initiating the following command: Run "ps-ef | grep- | Resource Manager."
Step 2: After identification of the worker node, then we have to execute the task by logging in to the node and run "ps –ef | grep- iNodeManager."
Step 3: Finally, we have to scrutinize the node manager log for most of the errors that are generated from users' level logs, that earlier created the problem in each Map Reduce job and are eliminated from the environment.

12) Define modes it helps Hadoop to run.
There are three different types of modes that help Hadoop to run and are as follows:
Pseudo-distributed mode: The peculiarity about this mode is that both the slave as well as the master node are the same here. They mostly work for the configuration of mapred-site.xml, core-site.xml & hdfs-site.xml files.
Fully distributed mode: This is a production stage where data is distributed across various notes on a cluster separating the master and the slave node allotments differently.
Standalone mode: Basically, this is the default mode used for debugging purposes, and in general, it does not support HD FS.
13) What are some of the practical applications of Hadoop?
In real-time, Hadoop makes a difference in fraud detection and prevention. -
- It also helps in advertisement targeting platforms.
- It adds to customer service in real-time by analyzing customer data.
- Practically with Hadoop, we get access to the unstructured data and improve services around it.
- The data can be related to medical science, banking, financial trading, forecasting, or any industry.
14) What do you mean by distributed cache?
A service by no map-reduce framework for having access to cache files whenever needed. Once a file is listed as cached for a specific job, the framework will make it available both in the system as well as in memory.
We can read the cache file and can add an array or hash map in the code.
Simple read-only text data files or complex files such as jars, archives, and others can be unarchived at the slave node and distributed further. The distributed cache Blacks notification if any alteration is made in that timestamp of the cache files.
15) What do you mean by WebDAV in Hadoop?
It is a set of extensions to HTTP that not only supports editing but also updating files related to WebDAV by sharing mounted as the file system and providing access to HDFS as a standard file system. It also helps us to expose the HDFS over WebDAV.
16) What is Sqoop in Hadoop?
It is a tool that is used to create transfer and enable this relationship of data transfer between an RDB MS & a Hadoop HDFS.
It can work along with MySQL & Oracle and export data from HDFS to the RDBMS and vice versa.
Hadoop Interview Questions and Answers for Experienced - Set 3
Here are the Hadoop Interview Questions and Answers for experienced professionals,
17) How would you define a job tracker schedule as a task?
A job tracker usually stays up to date with the cluster work by informing through the message about the number of available slots.
A task tracker is responsible for sending heartbeat messages for the job tracker in order to ensure its active condition job functionality.
18) What do you mean by data ingestion & data storage?
Data storage can be defined as a subsequent step after the ingesting of data. When we deploy big data solutions to extract data from different sources or repositories, The data is extracted and stored in HDFS. the NoSQL database, like HBase. It helps to work along in randomly reading and granting writing access for sequential access.
The final step, the concludes data processing is done through frameworks such as MapReduce, Spark, Apache Pig, et cetera. The biggest question is to take the decision in choosing the particular file format that is needed to be processed.
For this, we use schema evaluation by using patterns like accessing 5 columns out of 50 columns with process split ability in parallel mode. Files formats such as CSV, JSON, COLUMNAR, sequence files, and AVRO are used in Hadoop.
These files are an ideal fit for exchanging data between the existing and the external system. They also store both data and schema together in a record that best suits long-term storage with the schema.
With these files, we can block the level of compression. It helps us to specify an independent schema for reading the files.
19) What do you mean by rack awareness?
When all the data nodes are aligned and put together to form a storage area, especially in the physical location of the data node, then the whole concept is termed a rack in HDFS.
Each data node acquires a name node that helps us to select a closer data node depending upon the rack in formation. It helps us segregate the contents into data blocks in the Hadoop Cluster. The whole process is known as rack awareness.
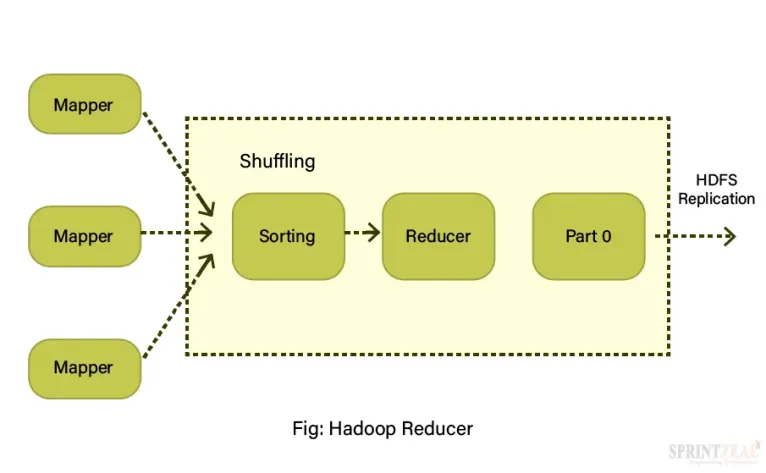
20) What do you understand by a Reducer?
A reducer involves three important steps to set up and reduce associated tasks in the following manner:
Setup()- in this step of the reducer, we configure various parameters or metrics to get a context out of the input data.
Reduce() is the key component of the reducer that helps us to associate per key with the reduced task.
Clean-up()- at the end of the method, we clear the temp files and create the space.
21) Define a Row Key?
It is a unique identifier in every row of the HBase table that helps to group cells logically & locates the same name in the server. It is otherwise called a Byte Array.
22) What are the different catalog tables in HBase?
In general, there are two important catalog tables found in HBase, namely ROOT & META. These tables help us to store all the regions as well as locate the META table in the HBase.
23) What are the different Hadoop configuration files?
The different Hadoop configuration files are:
core-site.xml
hdfs-site.xml
hadoop-env.sh
mapred-site.xml
master and slaves
yarn-site.xml
Top Hadoop Interview Tips
Some of the key tips are,
- Always be prepared for questions that are related to your personality.
- Work more on developing a positive aura around you one week before your interview. Doing this is fundamental to appearing quite confident to the interviewer and the panel.
- You should project open postures and groom yourself a little by having a professional hairstyle.
- The clothing also matters when you are out for the interview, as the job profile of a Big Data analyst or a Hadoop developer is more of analysis, dissecting, and synthesis.
- You must make sure to appear cordial to the sight. Avoid wearing Red or any shades of it. Do not go for black also, but grey is preferable, the best color would be White & green.
- Candidates have a tendency to sweat and lose calm during the competency test. You must understand that the questions asked in the test do have an answer.
- Focus on the process and remember that time works as a distractor. If you fail the competency test, then you skew the chances of your being in the Face-to-face interview round.
Conclusion
Candidates need to revise their studies once and take a day break to relax their minds before the interview day. If you have done certification in Hadoop, then it's well and good.
Overall, ensure to prepare well for the conceptual Hadoop questions like we have shared above. The interview is not at all difficult if you play the game by your own rules. The best part of the interviews is that you can hint at your interest and area of expertise in all your answers so that you can subconsciously direct your interviewer to ask you about your expertise.
Never stress out if your first interview was not as expected. Just remember to take feedback from the hiring authority when you sign off. This gives a great impression in the mind of the interviewer about you.
To know about the big data Hadoop analyst training, chat with our experts, and find the certification that fits your career requirements.
Get Big Data Hadoop Analyst Certification Training
Explore some popular Big Data course options like,
Subscribe to our Newsletters
Aradhya Kumar
With years of experience and a vast amount of knowledge in Project Management, Agile Management, Scrum, and other popular domains, Aradhya Kumar is well-versed in creating content for audiences from various fields and industries.
Popular Programs





Trending Posts

How to Become a Data Scientist - 2024 Guide
Last updated on Jul 22 2022

Data Visualization - Top Benefits and Tools
Last updated on Mar 27 2024
")
Big Data Guide – Explaining all Aspects 2024 (Update)
Last updated on Dec 12 2022

Apache Spark Interview Questions and Answers 2024
Last updated on Aug 30 2022

15 Best Python Frameworks for Data Science in 2025
Last updated on Mar 18 2025

Kafka vs Spark - Comparison Guide
Last updated on Jul 7 2022
Categories
- Agile Management 54
- AI and Machine Learning 42
- Big Data 53
- Business Management 51
- Cloud Computing 44
- Digital Marketing 56
- Information Security 8
- IT Hardware and Networking 17
- IT Security 103
- IT Service Management 29
- Leadership and Management 1
- Microsoft Program 2
- Other 43
- Programming Language 31
- Project Management 162
- Quality Management 75
- Risk Management 8
- Workplace Skill Building 2
Trending Now
Big Data Uses Explained with Examples
ArticleData Visualization - Top Benefits and Tools
ArticleWhat is Big Data – Types, Trends and Future Explained
ArticleData Analyst Interview Questions and Answers 2024
ArticleData Science vs Data Analytics vs Big Data
ArticleData Visualization Strategy and its Importance
ArticleBig Data Guide – Explaining all Aspects 2024 (Update)
ArticleData Science Guide 2024
ArticleData Science Interview Questions and Answers 2024 (UPDATED)
ArticlePower BI Interview Questions and Answers (UPDATED)
ArticleApache Spark Interview Questions and Answers 2024
ArticleTop DevOps Interview Questions and Answers 2025
ArticleTop Selenium Interview Questions and Answers 2024
ArticleWhy Choose Data Science for Career
ArticleSAS Interview Questions and Answers in 2024
ArticleWhat Is Data Encryption - Types, Algorithms, Techniques & Methods
ArticleHow to Become a Data Scientist - 2024 Guide
ArticleHow to Become a Data Analyst
ArticleBig Data Project Ideas Guide 2024
ArticleHow to Find the Length of List in Python?
ArticleHadoop Framework Guide
ArticleWhat is Hadoop – Understanding the Framework, Modules, Ecosystem, and Uses
ArticleBig Data Certifications in 2024
ArticleHadoop Architecture Guide 101
ArticleData Collection Methods Explained
ArticleData Collection Tools - Top List of Cutting-Edge Tools for Data Excellence
ArticleTop 10 Big Data Analytics Tools 2024
ArticleKafka vs Spark - Comparison Guide
ArticleData Structures Interview Questions
ArticleData Analysis guide
ArticleData Integration Tools and their Types in 2024
ArticleWhat is Data Integration? - A Beginner's Guide
ArticleData Analysis Tools and Trends for 2024
ebookA Brief Guide to Python data structures
ArticleWhat Is Splunk? A Brief Guide To Understanding Splunk For Beginners
ArticleBig Data Engineer Salary and Job Trends in 2024
ArticleWhat is Big Data Analytics? - A Beginner's Guide
ArticleData Analyst vs Data Scientist - Key Differences
ArticleTop DBMS Interview Questions and Answers
ArticleData Science Frameworks: A Complete Guide
ArticleTop Database Interview Questions and Answers
ArticlePower BI Career Opportunities in 2025 - Explore Trending Career Options
ArticleCareer Opportunities in Data Science: Explore Top Career Options in 2024
ArticleCareer Path for Data Analyst Explained
ArticleCareer Paths in Data Analytics: Guide to Advance in Your Career
ArticleA Comprehensive Guide to Thriving Career Paths for Data Scientists
ArticleWhat is Data Visualization? A Comprehensive Guide
ArticleTop 10 Best Data Science Frameworks: For Organizations
ArticleFundamentals of Data Visualization Explained
Article15 Best Python Frameworks for Data Science in 2025
ArticleTop 10 Data Visualization Tips for Clear Communication
ArticleHow to Create Data Visualizations in Excel: A Brief Guide
ebook